
「AIで情報収集を自動化したら、自分の発信負荷が一気に減る」。
そう思って、GAS(Google Apps Script)とClaude APIでRSS→AI要約→通知のパイプラインを作りました。
2026年4月に設計を始めて、6月に本番稼働。
約2.5ヶ月運用した今、結論から書きます。
負荷は確かに下がりました。
データは1,130行以上たまり、本番で動き続けています。
ただし、運用を続けるほど「AIに任せきれない場所」が次々と見えてきました。
4つのパターンに整理できます。
- AIは保守的に採点しすぎる(良い記事を捨てる)
- AIは他人事を自分の体験として書く(嘘投稿リスク)
- AIは見えない事故を起こす(同じ投稿を翌朝もう一度しかける)
- AIは「自分の在庫」を見ない(承認を1晩忘れると翌朝ゼロ)
この記事は、コードを書かない元社内SEがAIに実装させて作ったパイプラインを、2.5ヶ月運用した一次データの記録です。
rank分布の実数値・事故の詳細・改修したコードの中身まで、全部公開します。
同じことを試したい個人事業主・同業フリーランス、それから「AIに業務を任せたい」と考えている小規模事業者の方の参考になればうれしいです。

目次
なぜRSS→AI要約→通知を自動化したかったか
私はIT・AI・セキュリティ分野で個人事業を営んでいます。Xやブログで発信を続けたいのですが、現実には毎日の作業がきつい。
朝起きてGIGAZINE・ITmedia・TechCrunch・ASCII……を順番に開いて、今日の話題を眺める。
気になる記事をクリックして、本文を読む。
Xに何を投稿するか考える。
140文字に整える。
投稿する。
これを毎日やると、結構な時間が溶けます。
報酬につながる時間が、毎朝消えていく感覚でした。
発信を止めるという選択肢はありませんでした。
個人事業で「自分が何をやっているか」が見えないと、相談も受注も来ない。
発信を止めると認知が消える、認知が消えると個人事業の入口が閉じる。
この理屈は分かっていました。
そこで、コードを書かない私はAIに実装させることにしました。Claude Code(当時はまだCowork機能が出たての頃)に「GASでRSSを取って、AIで要約させて、Xに自動投稿する仕組みを作って」と頼んで、短期間で初版が動きました。


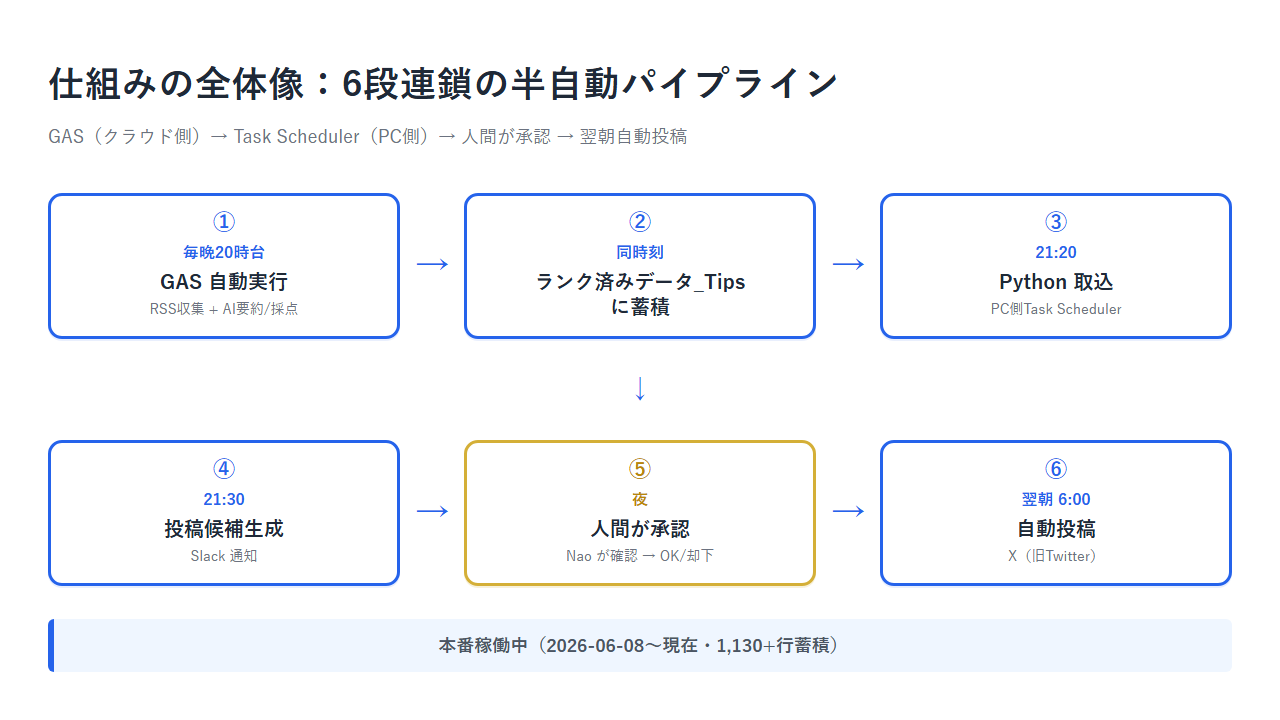
仕組みの全体像
最終的に動いているのは、こういう連鎖フローです。
- 毎晩20時台:GAS(runTipsPipeline)が自動実行され、RSSを巡回して新着記事をスプレッドシートに追加
- 同時にClaude APIでランク判定(S/A/B/C)と「投稿の切り口」を生成→「ランク済みデータ_Tips」シートに保存
- 21:20:Windows Task SchedulerでPython(x-auto-poster)が起動し、スプレッドシートからS/A記事を取得
- 21:30:別のPythonタスクが投稿候補を生成(フック・本文・ハッシュタグ込み)
- 夜:人間(私)が承認画面で投稿候補をチェックし、OKを出したものだけpost_queueに積む
- 翌朝06:00:post_queueの先頭1件をXに自動投稿
使っているツールは、GAS(無料・Googleアカウントだけで動く)、Claude API(モデルはclaude-opus-4-6を使用・公式モデルID一覧で確認)、Googleスプレッドシート、Python、Windows Task Schedulerです。
規模感を数字で書くと、「ランク済みデータ_Tips」シートは1,130行以上、これまでに蓄積。
投稿成功数は2026年6月時点で18件以上(手動承認を通したものだけ)。
本番稼働は2026年6月8日に「完全閉」として全工程を稼働状態にして、それ以降も継続中です。
ここまでは順調でした。
問題は、運用を続ける中で「AIに任せきれない場所」が次々と見えてきたことでした。
パターン① AIは保守的に採点しすぎる
最初に気づいたのは、2026年6月17日のことでした。
朝のチェックで「AI床偏重」という警告が出ていました。
AIが選んだS/Aランク記事の供給が薄くなり、私が事前に登録しておいた「つなぎネタ」(topic_backlog)ばかりが投稿される状態でした。
原因を探るためにスプレッドシートを見にいきました。
1,523行のランク判定済み記事の分布は、こうなっていました。
- 国内:S=26件 / A=200件 / B=422件 / C=552件
- 海外:S=3件 / A=48件 / B=170件 / C=102件
SとAだけ取り込む設定にしていたので、Bランク422件(国内)と170件(海外)は全部捨てていました。
海外(news_en)は約1ヶ月、利用可能な記事が0件という状態でした。
Bランクの中身を実例で見にいったら、ChatGPT/Gemini搭載車の話、FIDO2認証規格の動向、OpenAI規制調査、Anthropicモデルの利用制限など、AI/IT読者向けに十分な品質の記事がたくさん入っていました。
AIが「Bランク」と判定したのは、「保守的に採点して安全側に倒した結果」でした。
AIから見ると「Sは絶対外せない」「Aは強い切り口がある」と判定できないものをBに落としているだけで、捨てるほどではない。
対応は、Bランクを「補欠枠」として救出する仕組みを足しました。
S/A優先は維持しつつ、S/Aが薄い時はB(日次上限8件)から鮮度3日以内を選ぶ。
CランクだけはAIの「除外推奨」を信じて落とす。
学びは、AIのランク判定を実例で再評価する人間レビューのプロセスを最初から組んでおく、ということでした。AIが「これはB」と言ったから捨てる、を機械的に運用すると、半年で「良い記事を半分以上捨てている」状態が起きます。

パターン② AIは他人事を自分の体験として書く
これが一番ヒヤッとした事故です。2026年6月18日のことでした。
夜の承認画面に、こんなフック(投稿の冒頭1文目)が並んでいました。
「AIエージェントを24時間放置したら、105万円の請求書が届いた。」
素材は海外の実験記事でした。
誰かが実際にAIエージェントを24時間動かして、その結果105万円の請求書が来た、というニュース。
第三者の体験談です。
ところがフックには主語がありません。
これが私のアカウントから投稿されたら、読み手は「あ、こんちゃ(私)が24時間放置して105万円払ったんだ」と受け取ります。
事実と全く違う。
嘘投稿になります。
原因はAIに渡していた生成プロンプトの中にありました。
news系の1文目フックの指示に「逆張り体験文」という語が入っていて、これがAIに「他人事を自分事のように書く入口」を提供していました。
一方でシステムプロンプトの上位では「自分の体験ではない前提で書く」と書いてある。
指示が矛盾していたのです。
対応は2層で入れました。
1つは入口(生成プロンプト)から「逆張り体験文」を削除し、news系には「この出来事は第三者に起きたこと。
投稿者の体験として書かない(主語を省いた『〜したら…が届いた』も禁止)」と明記。
もう1つは出口(機械チェック)でnews系の一人称体験フックを検出して自動でFAIL扱いにする層を追加しました。
機械チェックは、第三者の存在を示す手掛かり(「海外」「ある運用者」「報じ」「事例」など)が一切無い一人称体験フックだけFAILにします。
「海外の実験で、AIエージェントを24時間放置したら105万円の請求書が届いたという報告があった」と書き直せば通る、というレベルの寛容な設計です。
学びは、AIは事実と捏造の境界を理解しないということです。プロンプトに矛盾があれば、AIは「言われたとおりに」書いてしまう。人間の承認が最後の砦ですが、承認の前に機械チェックで明らかな嘘候補を弾く層がもう1枚必要でした。
パターン③ AIは見えない事故を起こす
2026年6月21日、朝のXタイムラインを見ていて違和感がありました。前日に投稿したはずの記事が、もう一度同じ内容で投稿されようとしている気配があったのです。
確認したら、queue_035という投稿レコードが、こんな状態でした。
- 投稿は確かに2026-06-21 06:00に成功している(X側にtweet_idが返ってきている)
- 独立した投稿ログ(Markdownファイル)にも投稿成功が記録されている
- パフォーマンス計測ファイル(self_performance.json)にも投稿成功が記録されている
- ところが、本来の状態管理ファイル(post_queue.json)では、なぜか「pending」(未投稿)のまま残っている
このまま翌朝06:00を迎えると、自動投稿スクリプトは「pendingの先頭」を見て、queue_035の同じ内容をもう一度Xに投げます。
フォロワーは「あれ、こんちゃさん、昨日と同じこと投稿してる」と感じます。
信頼が削れます。
原因は1つのバグではなく、設計の弱さでした。
post_queue.jsonというファイルを、複数の処理経路(投稿実行・承認処理・古い記事の自動除外)が「読み込み→書き換え→保存」していて、しかも保存時に「他の経路がその間に書いた変更」を検知する仕組みがありませんでした。
古いスナップショットによる上書きが起きていたのです。
対応は、二重投稿を防ぐ仕組みを足しました。
具体的には、同じファイルを複数の処理が同時に書き換えるのを防ぐ「ファイルロック」(技術的にはportalockerというライブラリ)と、保存前に他の処理が割り込んで書いていないか確認するハッシュチェック。
それから「投稿する直前に独立記録(投稿ログMarkdown)を確認して、同じIDが既に投稿済みなら再投稿せず自動修復する」仕組み(技術的には冪等性ガード)を入れました。
投稿成功後の保存順も変えて、独立記録を先に書いてから状態ファイルを更新するようにしました。
学びは、自動化は「成功した」と「成功した記録が残った」を別物として扱う設計が要る、ということでした。AIが投稿に成功しても、状態ファイルが古いまま残れば、自動化は同じことを翌朝もう一度やります。独立した記録で「もう投稿した」を確認するルートを別に1本持っておく必要があります。

パターン④ AIは「自分の在庫」を見ない
これは2026年6月28日に気づいた話です。投稿頻度を立て直そうとして検証していて見えました。
パイプラインは「毎晩生成→人間承認→翌朝投稿」で回しています。
検証期間14日のうち、実際にXに投稿があったのは9日でした。
5日分、ギャップが出ていたわけです。
原因を6つのデータソースで照合した結果、こうでした。
- 毎晩の生成は健全に動いている(直近15回連続で成功)
- 未承認の候補は十分にたまっている(candidates_pending=20件で上限到達)
- ところが、人間が承認するタイミングが不定期で、承認を1晩飛ばすと、翌朝の「投稿可能な在庫(post_queue.pending)」が0件になる
- 朝06:00に投稿スクリプトが起動しても、pending=0なので何も投げず終了する
従来の監視は「未承認の候補も全部足した総バッファ」を見ていたので、未承認は健全(20件)だと「在庫は十分」と表示されていました。
実は「承認済みの投稿可能在庫」だけが空でした。
監視の盲点だったのです。
対応は、「承認済み在庫(post_queue.pending)の低水位モニタ」を新設しました。
3日分を下回ったら、夜の振り返り画面で「⚠️ 承認済み在庫が低水位です。
今すぐ承認しないと翌朝の投稿が止まります」と警告を出す。
それから「fill-buffer」コマンドを作り、週末にまとめて7件分の候補を承認し、月〜金は人間ノータッチで自動消化される運用に切り替えました。
学びは、自動化の中で人間の承認がボトルネックになる、ということでした。自動化を導入しても、人間が判断するゲートが間に挟まる以上、承認のタイミングと在庫設計を業務側で組まないと、止まる場所は技術ではなく運用になります。技術で自動化しても、運用設計で詰まる。これは現場でよく起きる構造だと感じました。
4パターンから見えた「AIに任せきれない部分」の本質
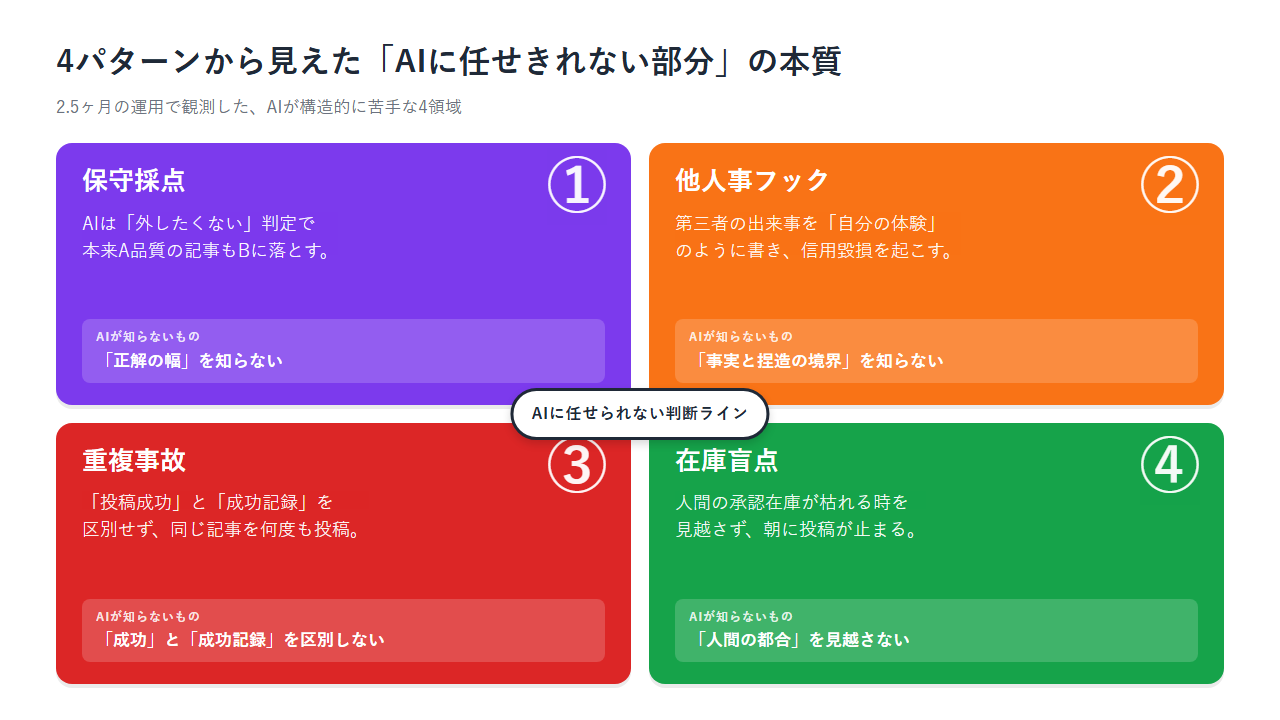
4つのパターンを並べると、共通点が見えます。
- パターン①は「正解の幅」をAIが知らない(保守採点)
- パターン②は「事実と捏造の境界」をAIが知らない(一人称誤認)
- パターン③は「成功した」と「成功記録が残った」をAIが区別しない(重複投稿)
- パターン④は「人間の都合」をAIが見越さない(在庫設計)
どれも「AIが間違えた」というより、「AIに任せて良い範囲」を最初に間違えた、という話です。
AIは「指示されたとおり」によく動きます。
指示の中に「正解の幅」「事実の根拠」「成功の独立確認」「人間の運用リズム」が入っていないと、AIはそこを補完してくれません。
つまり、AI自動化は「一度作って動かしっぱなし」では成立しません。
運用しながら『AIに任せて良い範囲』と『人間が判断する場所』のラインを引き直し続ける運用になります。
2.5ヶ月運用してみて、これが最大の学びでした。
個人事業主の方が同じ仕組みを作るなら、最初から「①AIスコアの実例レビュー②規約と機械チェックの両層③独立記録での成功確認④人間都合のバッファ」の4点を設計に組み込んでおくと、私のように半年かけて1つずつ発見せずに済みます。
もし会社(小規模事業者)でAI業務改善を始めるなら、この4パターンは「AIに任せて何が起きるか」の具体例として、最初の打ち合わせで担当者に共有しておくと、現場の納得感が違います。
「AIに任せると勝手に動く」という見方から、「AIに任せると、運用しながら判断ラインを引き直し続ける」という見方へ、最初から共通認識にできるからです。
具体的には、最初の段階で次の4点を決めておくと、私のように後から事故で発見せずに済みます。
①AIに任せる範囲(どこまで自動で動かすか)/②人間が判断する場所(どこで止めて承認するか)/③判断結果を残す場所(誰がどう判断したかの記録を、AIが上書きできない場所に残す)/④運用中に判断ラインを見直すタイミング(最初に決めたラインを、何ヶ月後に・何を見て見直すか)。
中小企業がAI導入を始める前に決めるべき項目は、経営側の論点(予算・優先順位・体制)も含めると別記事「中小企業のAI導入が失敗する前に決める5つのこと」にまとめています。
あわせて読むと、経営側の論点と現場側の論点が揃います。
よくある質問(FAQ)
Q1. コードを書けない人でも自分で作れますか?
私自身がコードを書きません(書けません)。
元社内SEで仕事の設計や手順書化はやってきましたが、コードを自分で書く役割ではありませんでした。
今もAIに「こういう仕様で実装して」と頼んで、出てきたコードをGASエディタに貼り付けています。
半日で初版が動いたのは、私が書いたわけではなくAIが書いたからです。
ただし、運用していると「AIに任せきれない部分」が4パターン出てきます。
ここを直す時は、AIに「こういう症状が出た。
原因を調べて直して」と頼みます。
直すのもAIですが、「何が問題か」を言葉にして渡すのは人間の役割でした。
Q2. Claude API以外(ChatGPT・Gemini)でも同じ仕組みは作れますか?
原理的にはどのAI APIでも作れます。
私がClaude Opus 4-6を選んだのは、ランク判定と切り口生成のような「文脈を読んで判断する」タスクで安定して品質が出る感触があったからです。
料金は2026年6月時点でClaude Opus 4.6が入力 $5 / 百万トークン・出力 $25 / 百万トークン(Anthropic公式料金ページで確認)。
ChatGPTやGeminiにも同等以上のモデルがあるので、慣れているAIで作るのが筋がいいと思います。
Q3. GASでなくZapierやMakeでも作れますか?
作れます。
ZapierやMakeはノーコードで組めるので、「RSS取得→AI要約→Slack/Discord通知」までならGASより早く動きます。
GASを選んだのは、無料で動くこと、ランク判定のロジックを細かく書き換えやすいこと、スプレッドシートをデータストアとして使えること、6分の実行時間制限はあるものの十分だったことです。
判定ロジックを細かく回したいならGAS、シンプルな転送だけならノーコードでいいと思います。
Q4. もし1から作り直すならどうしますか?
最初から4パターンの対策を入れます。
①Bランク(保守採点)も補欠枠で取り込む②news系プロンプトに第三者前提を明記+機械チェック層③投稿成功を独立記録で確認する冪等性ガード④承認済み在庫の低水位モニタ。
これらを後付けで足すと、その間に事故が起きます。
私の場合は「他人事を自分の体験として書く」フックが承認直前まで生き残った時が一番ヒヤッとしました。
向いてる人/向いてない人
向いてる人は、情報発信を継続したいけれど毎日の作業負荷で続かない方、自分の発信軸(「自分はこのテーマで発信する」)を言葉にできる方、AIが出した結果を自分の判断で「これは違う」と言える方です。
向いてない人は、「全部AIに任せて勝手に動かしたい」と思っている方、自分の業務の正解を持っていない方です。
AIは「正解の範囲」を持たないので、判断ラインを引ける人がいないと、4パターンが直らないまま事故が積み重なります。
まとめ
RSS→AI要約→通知のパイプラインを2.5ヶ月運用して見えたのは、AIに任せきれない場所が4つあること、そしてそれは「AI自動化のスタート地点で先に知っておけば、後から事故で発見せずに済む」ことでした。
もう少し本質的に言うと、AIは「正解の範囲」を持っていません。
私が経験から「これは違う」と分かることを、AIは知らないんです。
だから、自動化の本質は「AIに任せる範囲」を決めることより、「人間判断が要る場所を見つけること」のほうが大事だったと、2.5ヶ月運用して振り返ったとき思います。
同じことを試したい個人事業主の方は、最初から4パターンの対策を組み込んでスタートしてください。
2.5ヶ月で私が踏んだ事故を、踏まなくて済みます。
会社(小規模事業者)でAI業務改善を始める方は、この4パターンを「AIに任せて何が起きるか」の具体例として担当者と共有してください。
「勝手に動く」幻想がなくなり、「運用しながら判断ラインを引き直す」が共通認識になります。
この記事について
コードは書かず、業務側の視点からAIに実装させて、自分の業務を自動化した実録です。
「自分はコードを書かないけれど、AIで業務を変えたい」という方の参考になればうれしいです。
▶ ほかの自動化の実録もまとめています → 私が実際にAIで自動化した業務7選(実録まとめ)
▶ 同じような業務整理を相談したい場合は → できること・無料相談(Concha IT Nexus)
※本記事の料金・モデル名・APIプランは2026年6月時点の公式ドキュメントを参照しています。最新の情報は各サービス公式サイトをご確認ください。実装内容・効果は私の個人事業での2026年4月設計→6月本番稼働→現在までの運用結果であり、再現性を保証するものではありません。コードを書かない元社内SEがAIに実装させた一次データの記録としてお読みください。本記事はPRリンクを含みません。